Оглавление
Общая информация
Базовые принципы обмена данными
Обмен данными – это процесс, при котором какие-то данные из входящего набора данных (например, из текстового документа) физически переносятся в какой-либо другой формат хранения данных, например, в базу данных
Иными словами, перенос данных – это процесс, после которого данные, уложенные в формат 1, переходят в хранение в виде формата 2. Например, данные из табличного формата, текстового документа, переходят в данные, хранимые в формате базы данных, или в формат XML и т.п.
| Представление одних и тех же данных в Эксель или XML | Те же данные, уже находящиеся в БД ОпенКарт и выведенные для редактирования в панели администрирования |
| 
|
Идентификация данных при обмене одних и тех же сущностей (продуктов, категорий, и пр.)
Сущность данных – это однородные наборы данных, связанные по какому-либо семантическому признаку(ам). Например, товарные данные, данные о категориях вне зависимости от товаров, атрибуты или заказы и т.п.
Ключевой задачей при обмене данными между разными источниками является идентификация одних и тех же сущностей данных. Идентификация позволяет определить, куда назначаются те или иные данные, избежать дублирования одних и тех же сущностей данных, добавлять данные из разных источников в одну сущность данных, например, направлять разные данные в один и тот же товар, из разных файлов, находя такой товар по какому-либо идентификатору этого товара во входящих данных
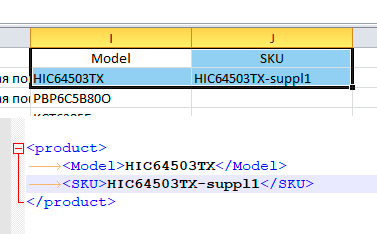
Наиболее точным идентификатором тех или иных данных является автоинкрементный идентификатор той базы, куда назначаются данные. Например, при импорте товаров, наиболее точным идентификатором будет значение product_id. Однако ввиду того, что автоинкрементные идентификаторы сложно иметь сразу во входящих данных, в качестве идентификатора используют какой-то независимый от базы данных код, составной или чистый, произвольный артикул, модель или унифицированные, стандартизированные идентификаторы складских позиций такие как: EAN, JAN, UPC, GTIN и другие
Идентификация работает следующим образом. После того, как в той или иной колонке файла поставлена настройка, что в данной колонке файла находится идентификатор, а также после указания, в какой колонке базы данных искать его соответствие. Перед импортом каждой строки с данными, скрипт ищет уже существующие данные, которые имеют соответствие. Если их нет, то в зависимости от режима обмена, данные или добавляются, как новые, или происходит обновление уже имеющихся данных, или происходит пропуск таких данных, например, если обмен идет в режиме добавлять только новинки
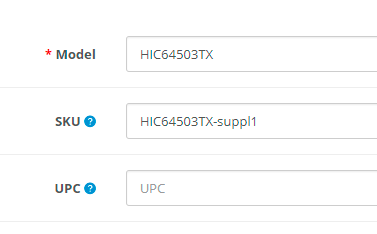
| 1. Колонка файла, в которой содержится идентификатор | 2. Настройка идентификации на колонку файла, в которой содержится нужный идентификатор (подробнее о настройке в соответствующем разделе) |
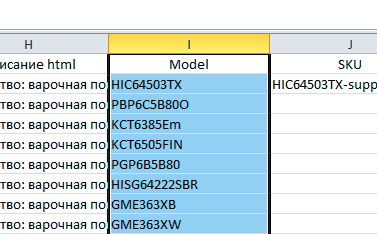
| 
|
| 3. После проверки наличия товаров с данным идентификатором, будет обнаружен товар (если есть), у которого в модели находится следующее значение | 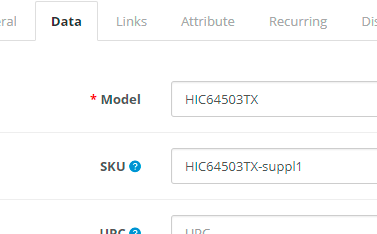
|
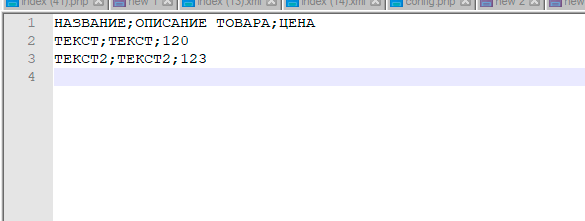
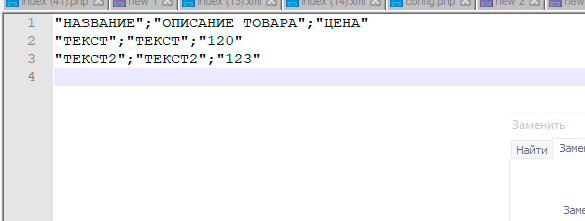
Примечание: пример файла, используемый в иллюстрации (формат CSV, разделитель: точка с запятой, ограничитель: двойные кавычки, кодировка: windows 1251)
Источники данных: файлы, ссылки на файлы на других сайтах, авторизация, файлы в архиве
В модуль импорта могут подаваться (в зависимости от версии) практически все распространённые источники с данными, в т.ч. архивированные в zip, или требующие стандартной авторизации по стандарту: RFC 7617
Подача того или иного источника рассмотрена в соответствующем разделе. Перед подачей файла или ссылки, ведущей на файл
Перед использованием того или иного источника с данными, нужно убедиться, что он представляет собой готовый файл, или файл, который начинает скачиваться по ссылке, если в качестве источника используется ссылка на файл.
Пример ссылки, которая ведет на файл для скачивания
Если файл расположен на сайте, и при вызове ссылки в браузере открывается не файл, а сайт (например, какой-то сайт Google Doc и т.п.), со ссылкой на скачивание, то такой сайт не может применяться в качестве источника. В этом случае, необходимо скачать файл, и подать файл, как файл.
Для упрощения работы с файлами, Вы можете копировать файл на собственный сайт, и подавать в модуль ссылку на файл на собственном сайте. Например, используя FTP, скопировать файл в папку image Вашего сайта, и передать в модуль ссылку типа: http://мой_сайт/image/file_csv.csv
При подаче файла в архиве, модуль извлекает первый файл внутри архива. Внутри архива не должно быть папок.
Кодировка данных
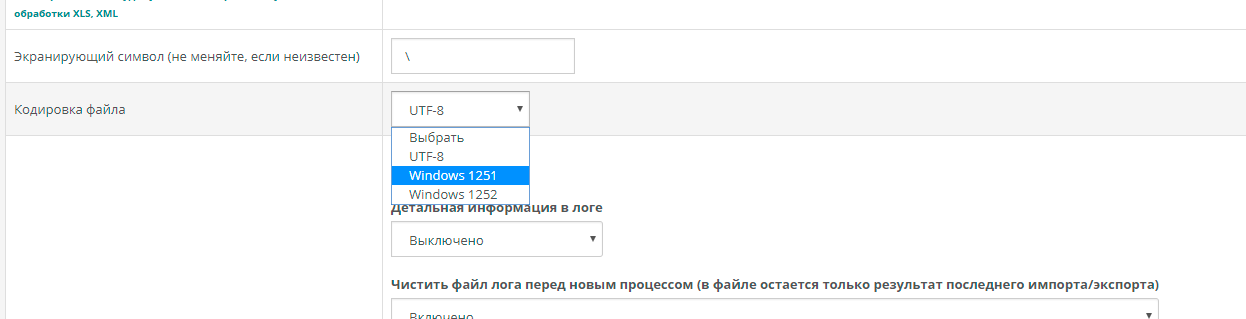
При использовании внешних данных, нужно приводить их к кодировке файловой системы и базы OpenCart. Кодировка базы и файлов OpenCart UTF-8. Если входящие данные поступают в какой-либо другой кодировке, то в модуле нужно установить кодировку входящих данных. После чего, при работе модуля данные будут конвертироваться в UTF-8.
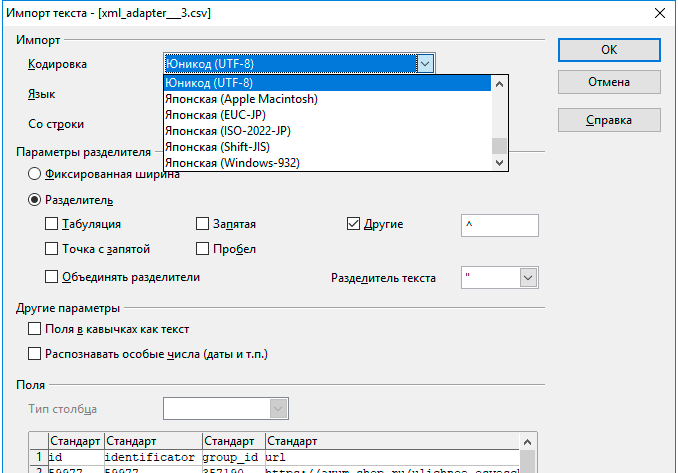
Установка кодировки файла при импорте, или для экспорта в файл, если входящая или исходящая кодировка должна быть не в UTF-8 (настройка находится здесь при импорте или здесь при экспорте) |
|
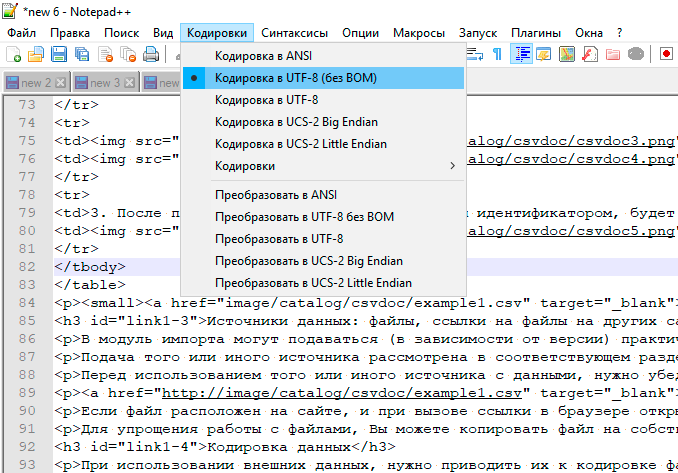
Узнать кодировку файла можно в программе NOTEPAD++, в ней же сделать перекодирование файла в UTF-8. Более качественную работу с CSV обеспечивает программа OpenOffice Calc, которая уже при открывании файла позволяет выбрать кодировку и таким образом, про тому, что будет показано в окне предпросмотра можно выяснить, как кодировка у файла. В этой же программе можно перекодировать файл, сохранив его с нужными разделителями, и в нужно кодировке – UTF-8
| Просмотр кодировки в NOTEPAD++ | Просмотр кодировки в OpenOffice Calc |
| 
|
Убедиться, что данные перекодированы верно можно по отсутствию «крякозябров» в области вывода данных, как это показано на следующих примерах
| Если данные нечитабельные, то кодировка неверная | Если данные читабельные, то кодировка верная |

| 
|
Важно! В связи с тем, что в средствах php ограниченные возможности по конвертации, и во избежание потери данных, а также для снижения нагрузки на сервер, которая понадобится на дополнительное действие – перекодировку, рекомендуется подавать данные сразу в кодировке UTF-8
Формат CSV/TSV/DSV - базовые знания
Формат CSV/DSV/TSV представляет собой – простой текстовый документ, посмотреть который можно в программах NOTEPAD++ или OpenOffice Calc.
Формат позволяет записывать данные в табличный вид, в котором в роли вертикальных ограничителей ячеек таблицы выступают т.н. разделители, а в роли новых строк таблицы – символ новой строки: \r\n
В случае, когда данные одной и той же ячейки идут в новых строках, но не являются новыми строками таблицы, такие данные ячейки дополнительно обертываются в т.н. ограничители текста
Листинг файла DSV с разделителем: | и ограничителем текстового значения в виде двойных кавычек: " В зеленый цвет показана область, которая будет восприниматься, как одна ячейка даже при том, что она разбита на строки. Так будет происходить из-за того, что область обернута в ограничитель (в данном случае двойные кавычки) | 
|
| Вывод, приведенного выше файла в программе OpenOffice Calc. Зеленая область соответствует зеленой области примера выше | 
|
Аббревиатура CSV – означает, что разделителем колонок в файле будет выступать запятая (от английского слова comma). Однако нужно всегда проверять, какой именно разделитель используются. Часто смысл аббревиатуры игнорируется, и формат CSV, на самом деле, представляет собой файл в формате DSV
DSV – это аббревиатура, означающая, что перед Вами текстовый документ, с каким-то разделитель колонок (от английского словам delimiter). Каким именно можно узнать из описания к формату, или после просмотра файла в текстовом редакторе, например, NOTEPADE++.
Менее используемыми в веб, является формат TSV - аббревиатура, означающая, что перед Вами текстовый документ, с разделителем колонок в виде символа табуляция.
Разделитель в форматах CSV/DSV/TSV
Разделителем называют какой-нибудь символ, который позволяет программе, интерпретирующей данные, узнать, где заканчивается одна ячейка табличной записи одной и той же строки и начинается другая. В примере, ниже приведен листинг текстового документа DSV, с разделителем – вертикальная черта: |
| Листинг данных в формате DSV с разделителем вертикальная черта: | | 
|
Разделителем может быть любой символ, в единственном числе, например, точка с запятой. В этом случае, запись данных будет выглядеть следующим образом
Листинг данных в формате DSV с разделителем вертикальная черта: ;
| 
|
Если какие-либо данные отсутствуют в ячейке, то разделители идут друг за другом без символов
Листинг данных в формате DSV с разделителем точка с запятой: ; и пустыми ячейками
| 
|
Таким образом, два разделителя, которые идут друг за другом образуют пустую ячейку таблицы, если вывести файл в программе Эксель или OpenOffice Calc
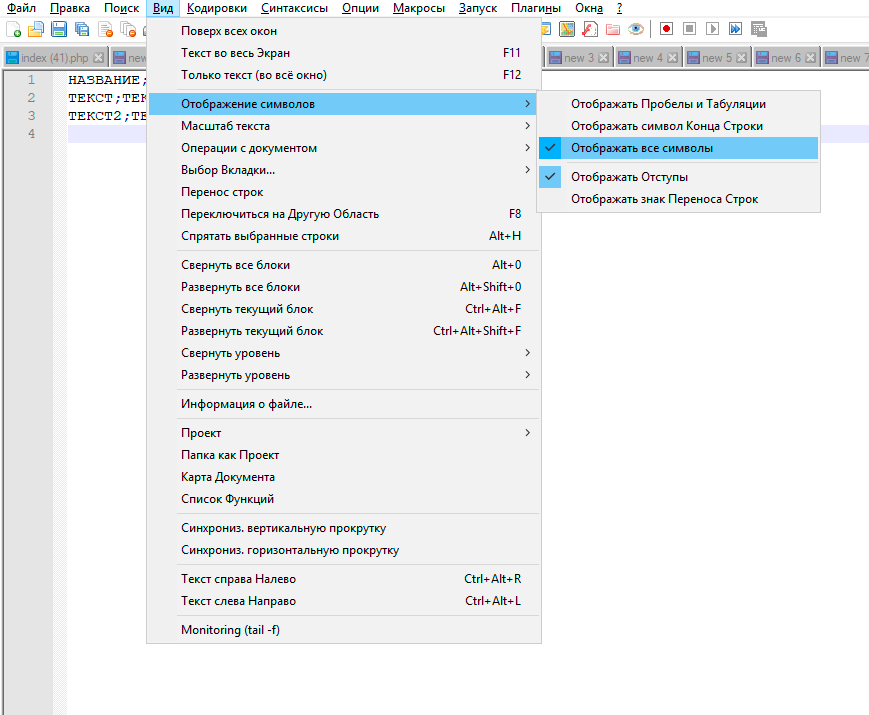
Строки текстовых документов DSV разделяются символом новой строки. Такой символ образуется автоматически, если нажать на клавишу enter в программе notepad++. Символ новой строки относится к символам, не имеющим графического вывода и поэтому он не виден в текстовых документах
| Включение видимости символов, не имеющих графического вывода в программе NODEPADE_++ |
|
В программе NOTEPAD++ можно увидеть такие символы, если выбрать соответствующий режим видимости
В примерах выше такой символ показан записью: \r\n, а в примере ниже, в программе NOTEPAD++ такой символ будет показан черными квадратами с вписанными в них буквами: CR LF
Если в файле DSV, есть символы новой строки, которые при этом должны находиться в одной ячейке, то такую ячейку оборачиваются слева и справа в символ: ограничитель текстовой ячейки
Листинг данных в формате DSV с разделителем точка с запятой, в программе NOTEPAD++ Символы новой строки показаны: CR LF | 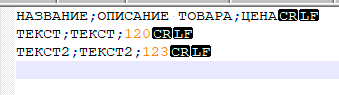
|
Ограничитель текстовых данных в форматах CSV/DSV/TSV
Если в файле DSV, есть символы новой строки, повторяются символы разделителя или самого ограничителя, но которые при этом должны находиться в одной ячейке, то такую ячейку оборачиваются слева и справа в символ: ограничитель текстовой ячейки
Для чего нужен ограничитель ячеек, если ячейка и так ограничена разделителем (см. главу Разделитель)? Действительно, ограничитель нужен не всегда. Но нужен обязательно, если в текстовых данных встречается символ разделителя, или символ ограничителя, или есть новые строки, но такие строки не нужно интерпретировать программе, как новые строки таблицы, такие разделители не нужно использовать для деления на колонки.
Три основных случая, для чего нужен ограничитель, представлены в таблице ниже: когда в ячейке встречаются символы новой строки, но это не строки таблицы; когда в ячейке встречаются символы разделителя, но это не разделитель и когда встречается символ ограничителя, но это не ограничитель

|
| В приведенном примере видно, что одна ячейка таблицы содержит и символы новой строки (показаны зеленым цветом), и символы ограничителя – двойные кавычки, показаны розовым, и символы разделителя – точка с запятой – показаны синим. Если не обернуть такие данные в разделитель – двойные кавычки (или любой другой), то данные не будут размещены в ячейках, как показано в листинге ниже в примере |
В примере видно, что ограничитель позволил программе взять данные внутри, как одну ячейку, а не создать новые строки таблицы или ошибочно создать колонки новые колонки
| 
|
Примечание: пример файла, используемый в иллюстрации (формат CSV, разделитель: точка с запятой, ограничитель: двойные кавычки, кодировка: windows 1251)
Символ экранирования
Символ экранирование – это символ, который позволяет экранировать разделители, если в файле CSV/DSV/TSV не указан символ ограничителя. Данный символ, в виду более узкого применения практически не используется, но всё еще является обязательным при парсинге формата. Если по в файле импорта символ экранирования не известен, то укажите символ обратного слеша: \
Как узнать, какой разделитель, какая кодировка и какой ограничитель используется в том или ином файле CSV/DSV/TSV
Чтобы узнать, какой разделитель используется в том или ином файле, откройте его в программе NOTEPAD++, и визуально определите, какой символ используется в качестве разделения колонок. На указанном примере – это символ точка с запятой
Чтобы узнать, какой ограничитель текста используется в том или ином файле, откройте его в программе NOTEPAD++, и визуально найдите символы, которые находятся внутри разделителей, но не являются частью данных. На указанном примере – это символ двойные кавычки
Чтобы узнать кодировку данных в файле, откройте файл в программе NOTEPAD++ и найдите, какая именно кодировка будет отмечена галкой, как на примере
Проверка валидности файла в формате CSV/DSV/TSV
Валидность формата – это соответствие формата спецификации, а точнее – соответствие упаковки данных внутри формата тем ожиданиям, которые есть от указанных данных.
Проверку валидности форматов CSV/DSV/TSV лучше всего осуществлять в программе OpenOffice Calc. Достаточно открыть файл, указав разделитель, ограничитель и кодировку, и увидеть результат парсинга этой программы - проверить таблицу, которая появится после открытия файла
| При открытии файла CSV/DSV/TSV в OpenOffice Calc укажите 3 параметра: кодировку файла, разделитель, и ограничитель текста (на примере называется разделителем текста) | 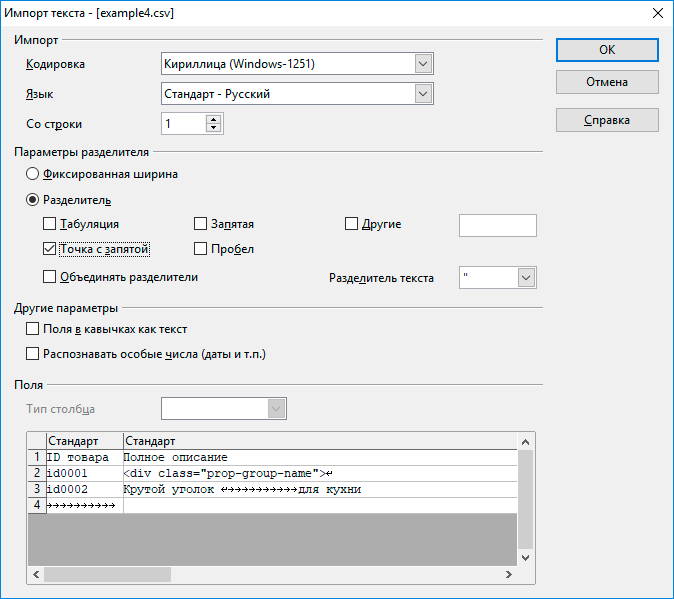
|
| После открытия, убедитесь, что данные файла выведены в табличном виде, и не перемешаны | 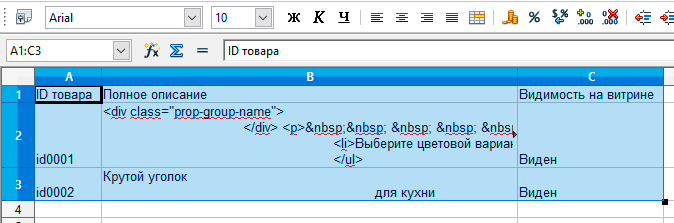
|
В модуле также можно проверить валидность данных. Если, в указанной в примере области данные выводятся без «кракозябров» - кодировка установлена верно. Также, если таблица соответствуют ожиданиям от упаковки, то есть все данные находятся в своих ячейках, в нужных колонках, то файл валидный. Если что-то не соответствует, то нужно открыть файл в NOTEPAD++ или OpenOffice Calc и исправить файл так, чтобы файл стал валидным
| После открытия файла в модуле, на Шаге 2, появится кнопка "Результат проверки файла". Кнопка раскрывает область, в которой в табличной форме приведена первая и последняя строка файла с данными. Если таблица не "сломана", в файле нет критических ошибок в упаковке данных. Если данные читабельные, то кодировка установлена верно | 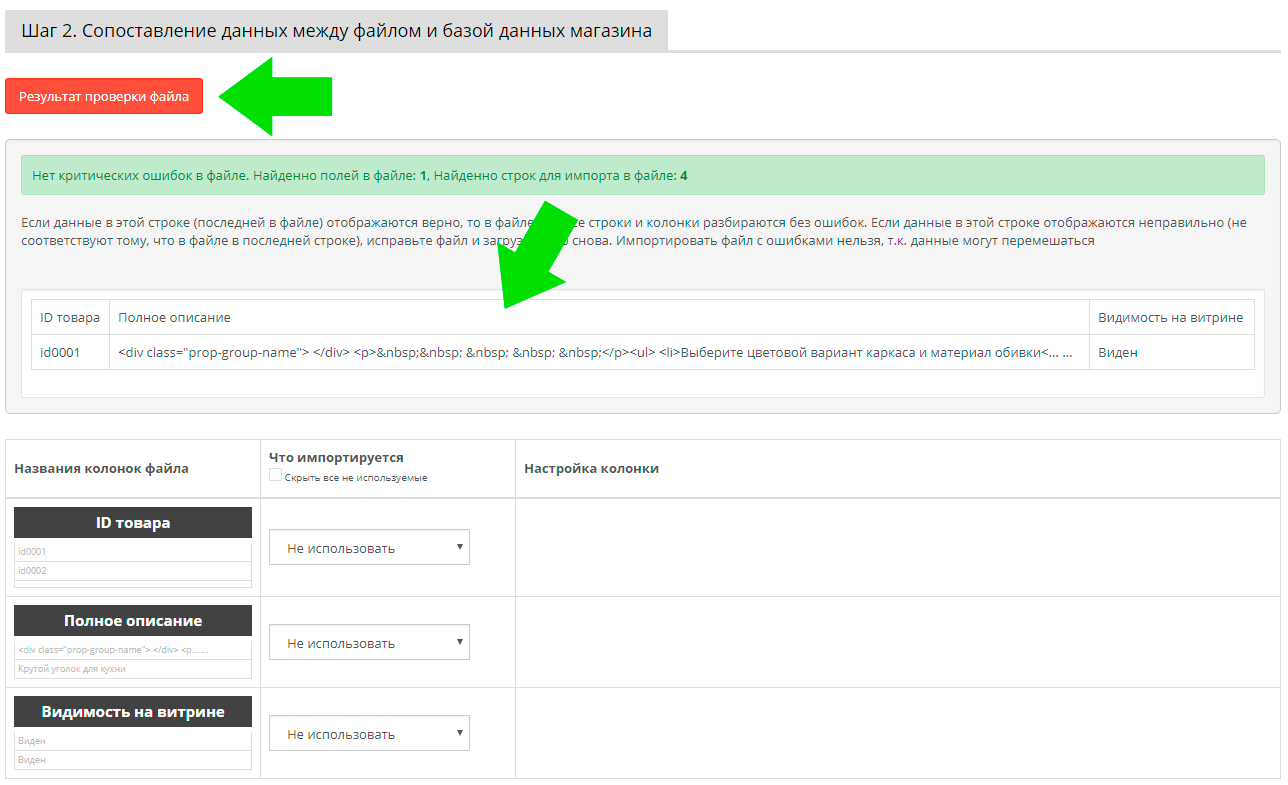
|
Требования к файлу CSV/DSV при использовании модуля
Кодировка файла – любая, из числа возможных в php на данный момент. Полный список кодировок можно уточнить по этой ссылке
Название колонок файла и последовательность может быть любой. Единственное требование состоит в том, что колонки должны иметь разные названия. То есть двух колонок с названием Цена, быть не должно, какая-то из колонок в этом случае должна быть названа Цена 2
В названиях колонок могут присутствовать любые символы, они могут быть на любом языке
Наличие названий колонок в файле обязательно
Формат XLS, XLSX, XML (YML) - базовые знания и валидация данных в этих форматах
Формат XLS - это формат записи файла, разработанный компанией Майкрософт. Проверка данного формата, осуществляется в программе Эксель или OpenOffice Calc. Если в этой программе файл не открывается, или открывается с ошибками, то парсинг такого файла, скорее всего, приведет к ошибкам. При использовании файла эксель, важно привести его к виду, при котором в шапке документа, а также по его сторонам будут отсутствовать лишние строки и колонки.
Форматы XLSX, YML - это разновидности базового формата XML. Проверять валидность этих файлов можно, отрыв их в редакторах XML, или в программе Эксель. Файл в формате YML можно также проверить, открыв его в браузере.
Формат XML, в т.ч. XLSX, YML вне зависимости от конкретного вида верстки имеет ряд требованиям к данным внутри тегов и атрибутов тегов. Базовые требования, приведены в таблице ниже
| Символ | Должен присутствовать в данных в следующем виде |
| & | &
|
<
| <
|
>
| >
|
'
| '
|
"
| "
|
Формат XML также, как и CSV, DSV имеет кодировку. Кодировка файла XML указывается в первой строке файла, как это показано ниже. Работать с кодировкой нужно также, как и при работе с кодировками в файлах CSV/DSV
| Пример первой строки XML файла, в которой сообщается о кодировке данных этого файла |
| <?xml version="1.0" encoding="utf-8"?> |
Вопросы производительности, достаточности ОЗУ, времени работы скрипта и дополнительные параметры хостинга, влияющие на производительность и её ограничение
Расчет ОЗУ (RAM) для работы с данными при импорте
Оперативная память, устанавливается на хостинге в каждом тарифном плане до определенного предела. Будьте внимательны, даже, если Вы покупаете хостинг с высокой ОЗУ, совсем не обязательно, что данный размер памяти уже включен. Очень часто память стоит по дефолту, и установка памяти, доступной для сайта по тарифу, должна производиться самостоятельно. Установка памяти, как правило, происходит добавлением в файл .htaccess директивы:
php_value memory_limit 1024М
Будьте также внимательны, если на хостинге используется какой-либо обратный прокси-сервер (например, NGINX) и другие параметры, то они могут сужать память на определенных аппаратных участках. Например, общая память хотя и может составлять 256М, на каком-либо участке её размер может быть установлен в районе 64М. Устранять такие несоответствия нужно, в ходе работы на конкретном хостинге, путем обращения в службу технической поддержки. Как правило, такие ошибки отмечаются в работе кодом 500 или 502, или вообще никак не отмечаться в логе сервера.
При расчете памяти нужно иметь ввиду следующее. Если физический размер файла 1Мб, то в ОЗУ такой файл будет присутствовать объектом, или массивом PHP. Размер файла может вырасти от 2 до 20 и даже 50 раз в зависимости от тех или иных настроек хостинга и характера данных в файле (кириллические символы занимают значительно больше ОЗУ, чем латиница). Таким образом, при работе с файлом размером 100Мб, Вам может понадобится ОЗУ, как минимум, 256Мб, но на практике, с учетом того, как настраивается большинство хостингов, и какого рода данные находятся в файлах, не менее 1024Мб, или даже 4-10Гб.
Приобретать большой объем памяти сразу не нужно. В модуле реализованы ряд средств, которые позволяют снизить объем потребления ОЗУ. Таким образом, если памяти будет не хватать, в этом случае, можно четко рассчитать необходимый объем ОЗУ с учетом конкретного хостинга, файла и данных в нем
Расчет времени выполнения скрипта
Время работы скрипта – это количество времени в секундах, которое будет отводиться хостингом на работу скрипта php. Время на работу скрипта выставляется, как правило, в файле .htaccess директивой:
php_value max_execution_time 640
Недостаток времени на работу, приводит к принудительной остановки хостингом работы скрипта. Как правило, после остановки, сервер уведомляет об этом ошибкой 504
Если на хостинге используется какой-либо обратный прокси-сервер (например, NGINX) и другие некоторые параметры, то они могут сужать время работы скрипта на определенных аппаратных участках. Например, время хотя и может быть установлено в пределах 600 сек, на которых участках работы сайта остановка будет происходить через 30 сек, и даже менее. Приведение в соответствие времени в этих параметрах осуществляется через обращения к специалистам службы поддержки хостинга
При расчете времени при работе модуля нужно иметь ввиду следующее. Если параметр нормы импорта (сколько строк с данными проходить за один раз) будет большой, но при этом в файле будет много колонок с разными данными, то, время его обработки будет значительное
Чтобы этого времени хватало на обработку одной порции, при большом количестве данных, устанавливайте небольшую норму импорта. Если же данных в файле немного (2-3 колонки и т.п.), то норма импорта может устанавливаться в несколько раз больше.
При этом, если ОЗУ много, то минимальная норма может быть 1000 строк, а максимальная 5000 строк, и вся работа будет происходить всего за 30 сек. Но если ОЗУ немного, то минимальная норма импорта должна быть установлена в районе 50, максимальная в районе 200, и время не менее 30 сек.
Работа с большими файлами
При работе с большими файлами (от нескольких десятков тысяч строк) не рекомендуется использовать т.н. шаред тарифные планы хостингов, т.к. на таких тарифных планах, заявленные по тарифу ресурсы, одновременно относятся ко всем сайтам, которые присутствуют в определенном сегменте. Таким образом, ресурсы постоянно будут меняться в зависимости от того, какие ресурсы будут потребляться в данный момент времени другими сайтами. Для работы с большими файлами, и большим объемом данных, на хостингах существуют т.н. тарифы: виртуальные сервера, или отдельные выделенные сервера, где ресурсы потребляются только теми сайтами, которые установлены и работают на данном конкретном виртуальном или выделенном сервере
Подбор ресурсов осуществляется администратором сайта, в зависимости от поставленной им задачи и с учетом того объема данных, который планируется использовать при импортно-экспортных операциях сервера.
Максимальные затраты времени нужны при работе с изображениями
Наиболее затратными по времени является работ с изображениями тогда, когда они закачиваются со сторонних серверов, обрезаются модулем при импорте, экспорте. При этом нужно учитывать, что время ответа сервера, с которого забирается изображение, может варьировать от десятых долей секунды на ответ, до десятков и более секунд на один ответ (на одно изображение). Влиять на это время невозможно. И длительные ответы могут быть связаны с частыми обращениями на эти сервера в короткий период времени, как происходит, когда за одну секунду может прийти запрос на 100 картинок.
При работе с изображениями, время работы скрипта может составлять от 10 изображений в одну секунду до 0,10 изображений в секунду (1 изображение за 10 секунд) и более.